

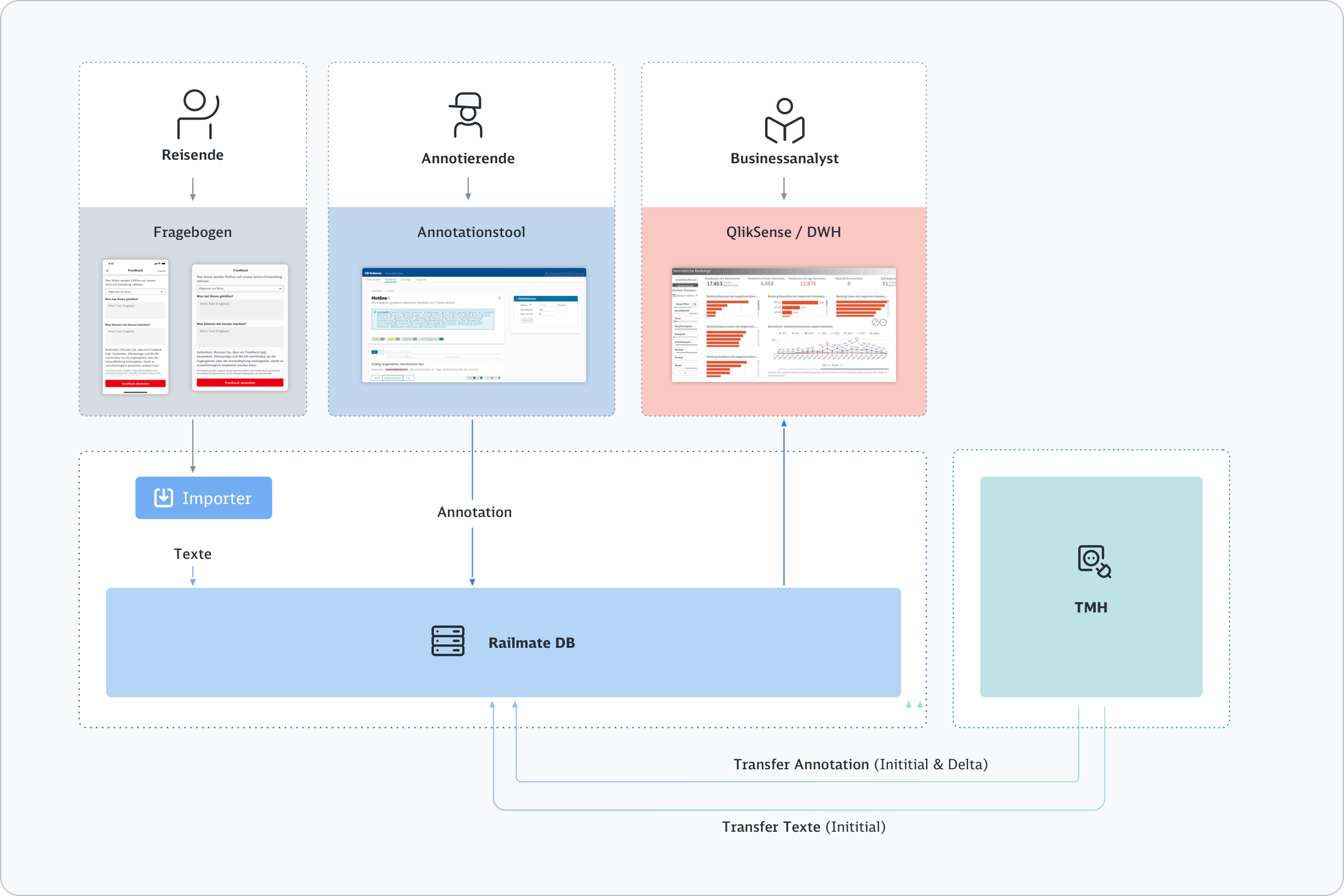
Technische Architektur
Die technische Architektur von Railmate basiert auf der losen Kopplung von Komponenten mit dezidierten Funktionen, wie sie nachfolgend beschrieben sind. Ein Streaming über Kafka erlaubt eine Event-gesteuerte Kommunikation zwischen verschiedenen Akteur:innen der Railmate-Landschaft.
Fragebögen
Die Fragebögen werden entweder über Dienstleister oder intern gehostet und bieten die Option der Eingabe über Freitextfelder. Neben den Texten werden die Eingangskanäle, Zeitstempel und weitere betriebliche Informationen (Zug und ggf. Wagen) gespeichert.
Importer
Railmate-Import-Apps importieren zeitgesteuert Daten aus Fremdsystemen nach Railmate. Sie extrahieren aus den Fremddaten die für Railmate notwendigen Informationen und stellen diese anderen Systemen über das Streaming bereit. Als Beispiel werden – neben dem Import von Interviews – zusätzlich Daten aus FRED, SAPL und dem Wagenreihenservice importiert. Zur Zeit unterteilen sich die Importe für einzelne fachliche Entitäten weiter, wie bei Interviews, in Roh-, Interview- und Stammdaten-Importer.
Annotationstool
Für Annotator:innen gibt es ein Annotationstool mit dem neue Annotationskampagnen für Kategorien angelegt werden können. In den Kampagnen können neue oder vorläufig erkannte Feedbacks bewertet werden. Die daraus resultierenden Annotationen können für das Training und die Evaluation von Machine Learning Modellen genutzt werden.
Railmate DB
Alle Daten werden in einer Railmate DB (Datenbank) abgelegt. Die Daten werden aggregiert, komprimiert und für den Zugriff optimierte Datenablagen herstellt (z.B. FactFeedback). Zusätzlich werden zeitgesteuert Mappings zwischen fachlichen Entitäten hergestellt.
Qlik und Reports
Es existieren verschiedene Zugriffsmöglichkeiten auf Daten und Analysen in Railmate.
Qlik und Reports
Es existieren verschiedene Zugriffsmöglichkeiten auf Daten und Analysen in Railmate.
Ad hoc Analyse
Datenanalyse Tools, die vorgefertigte Dashboards und/oder Eingabemasken zur Datenanalyse bereitstellen. Hierfür stehen auf QlikSense Dashboards für verschiedene Anwendungsfälle zur Verfügung.
Reports
Über Reports werden in regelmäßigen Intervallen Reports, mit einer aggregierten Sicht auf die Daten, versendet. Die Datenbasis kommt hierbei aus der Railmate DB.
TMH – Text Mining Hadoop
Innerhalb von Railmate wird eine Textanalyse durchgeführt. Alle Texte aus Datenimporten werden via Streaming und Datentransfer an diese übermittelt. Die Textsuche führt ein Pre-Processing durch, ermittelt Relationen und Negationen.
Klassifikation
Die Klassifikation klassifiziert alle Texte in einem Streaming-basierten Ansatz. Dazu werden neue Texte vom Datentransfer aus der Textsuche abgefragt und über das Streaming der Klassifikation zur Verfügung gestellt. Die Ergebnisse der Klassifikation werden via Streaming -> Datentransfer im Storage des DWH abgelegt. Das Publizieren der Ergebnisse im Streaming ermöglicht es anderen Interessierten, Event-basiert auf das Vorliegen neuer Klassifikationen zu reagieren.
 Weiter
Weiter